Abstract
Diffusion transformers (DiTs) achieve state-of-the-art image and video
generation, but their multi-step sampling and growing parameter count make
inference expensive. Post-training quantization (PTQ) is the natural remedy,
yet DiT activations shift across timesteps, prompts, and guidance branches,
forcing prior methods to re-fit calibration data for every new checkpoint or
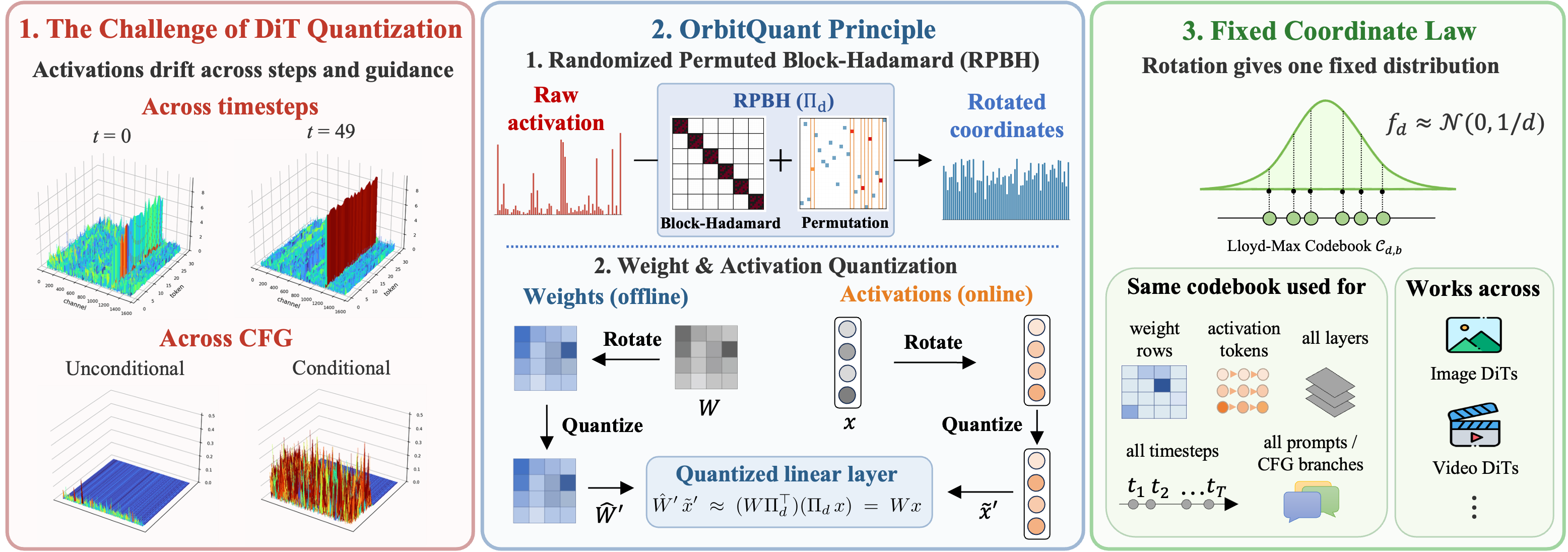
modality. We present OrbitQuant, a data-agnostic
weight-activation quantizer that bypasses range estimation by quantizing in a
normalized, rotated basis. In this basis, a randomized permuted block-Hadamard
(RPBH) rotation concentrates each coordinate around one fixed, known marginal
regardless of the input, so a single Lloyd–Max codebook serves all
timesteps, prompts, and layers of a given input dimension. We extend the same
quantizer to weight rows offline, absorbing the rotation into the weights so
that it cancels inside each linear layer and only a forward rotation on the
activations remains at runtime. The same recipe transfers from image to video
with no per-modality tuning. Across FLUX.1, Z-Image-Turbo, Wan 2.1, and
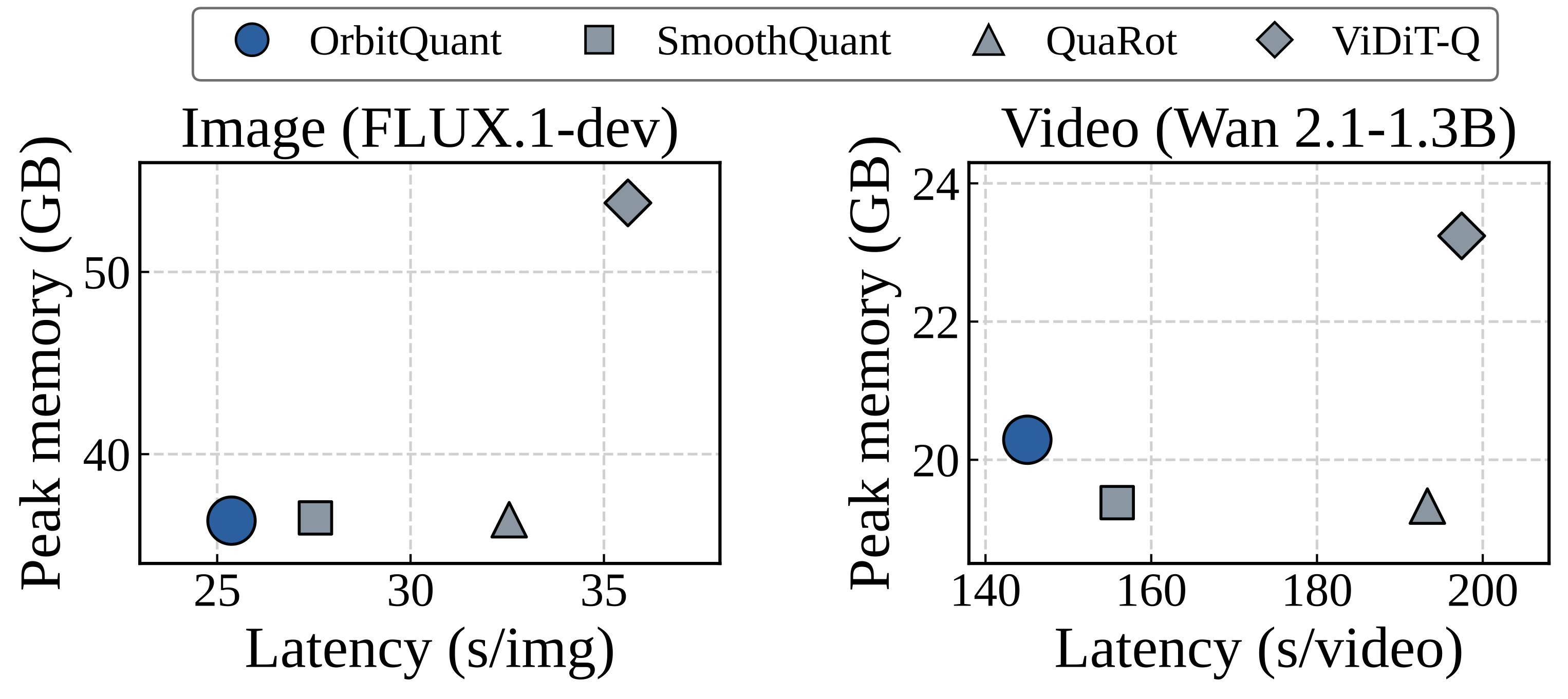
CogVideoX, it sets the state of the art for PTQ at several low-bit settings.
It also pushes PTQ of image diffusion transformers to 2-bit weights and 4-bit
activations with usable generation quality.
 OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers